Training a language model to run on RP2040
 Is it possible to train a Language Model to run on the RP2040? Yes. Dumb but fast
Is it possible to train a Language Model to run on the RP2040? Yes. Dumb but fast
Background
I have a TinyPico (RP2040) laying around the office for the last 8 months. During a recent hackathon, I decided to whip it out for a weekend project and thought to myself - I bet I can make a Language Model run on this.
 (pic of the robotics team I helped out)
(pic of the robotics team I helped out)
What I setout to do:
- Find a Language Model architecture that runs well on RP2040
- Train a model
- Run to the model
What I did:
- Tested different hyper-parameters & parameter count (1-28k) on the Pico itself
- Trained most optimized models on the TinyStories dataset
- Finding: Due to memory fragmentation on RP2040, I could not fit more than 256 vocabulary on the SRAM due to memory fragmentation

Model Architecture
I analyzed 5 factors of the Language Model Architecture & how that affects model inference speed as well as model quality:
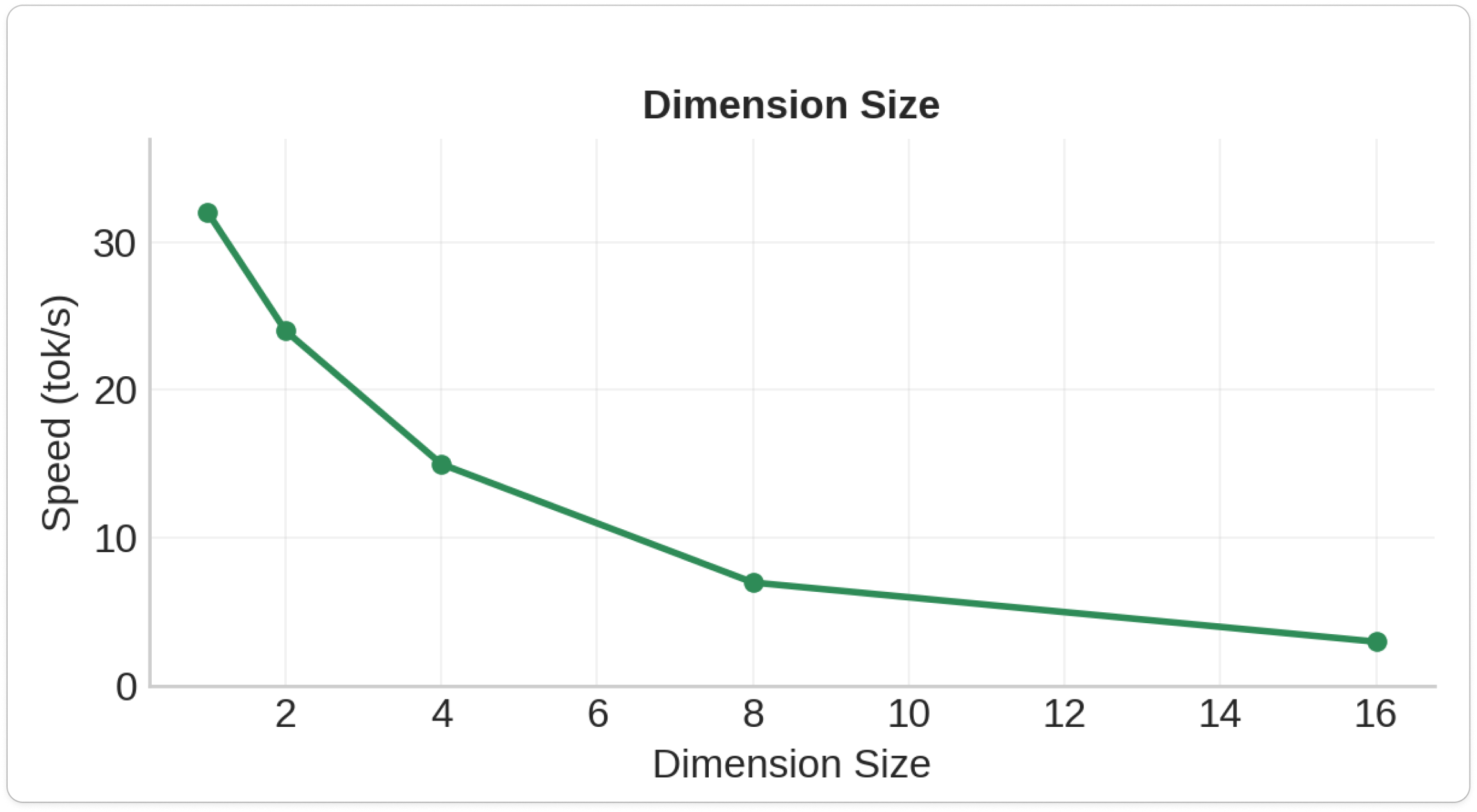
1.Dimension size
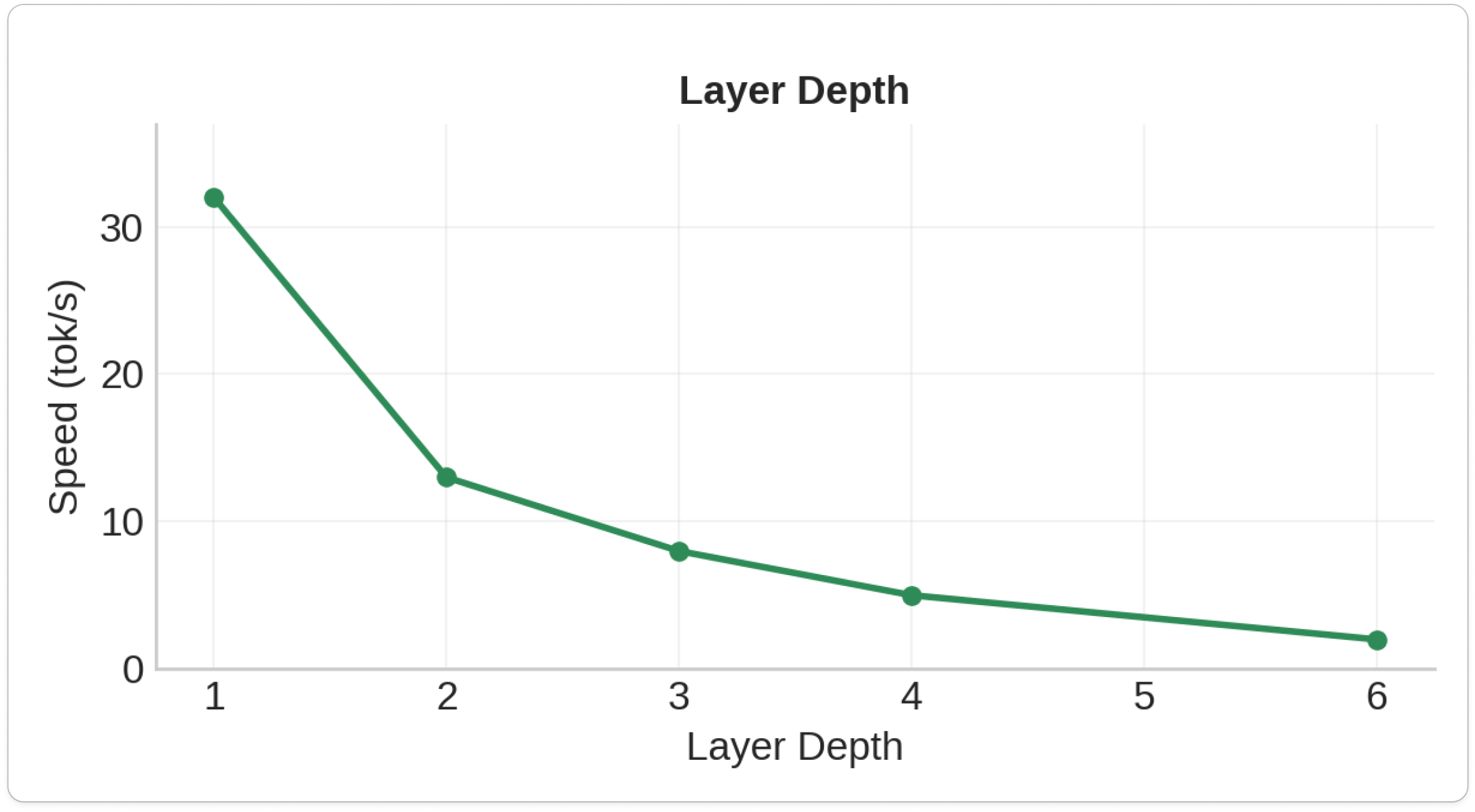
2.Layer Depth
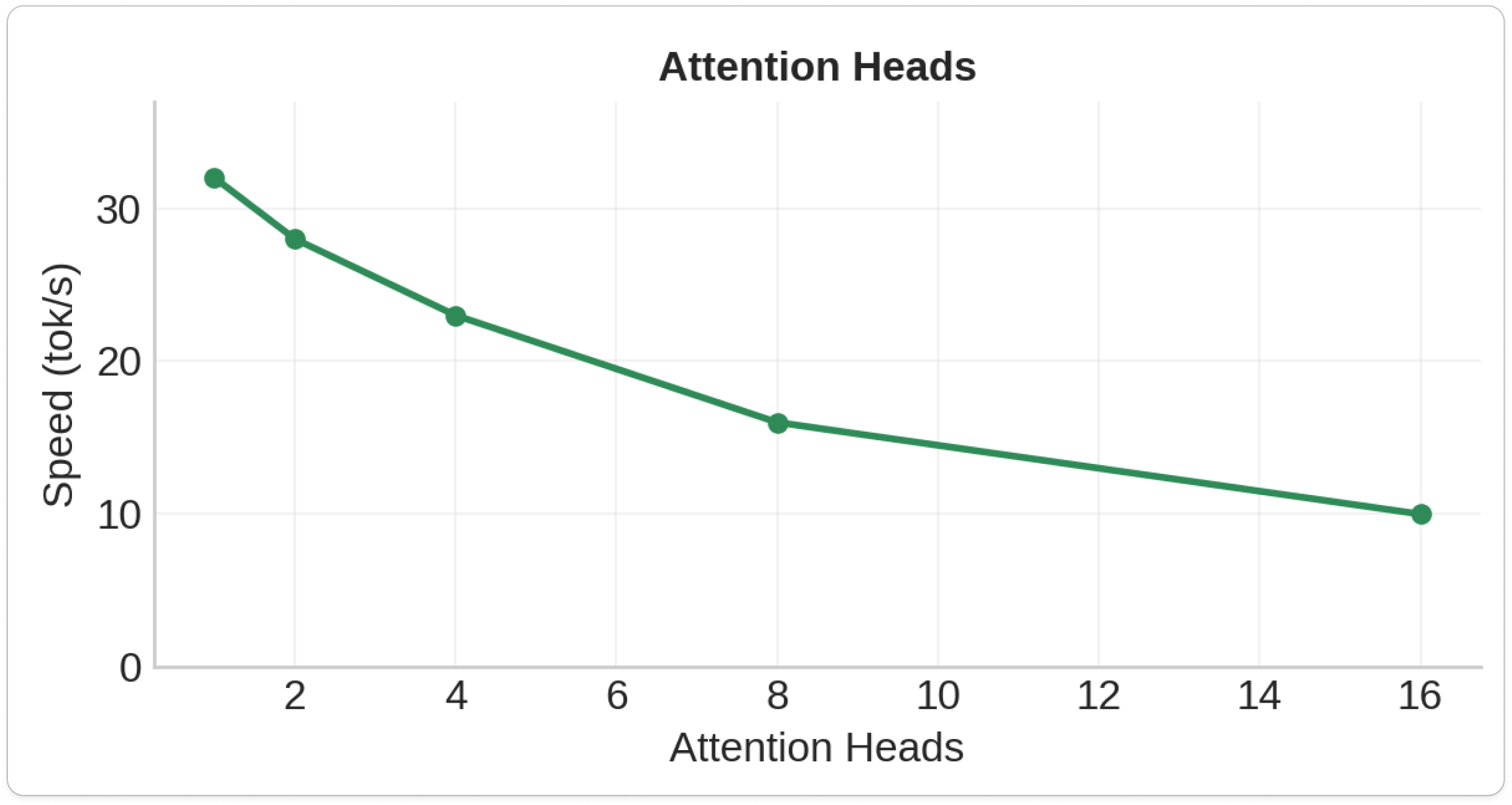
3.Attention Head count
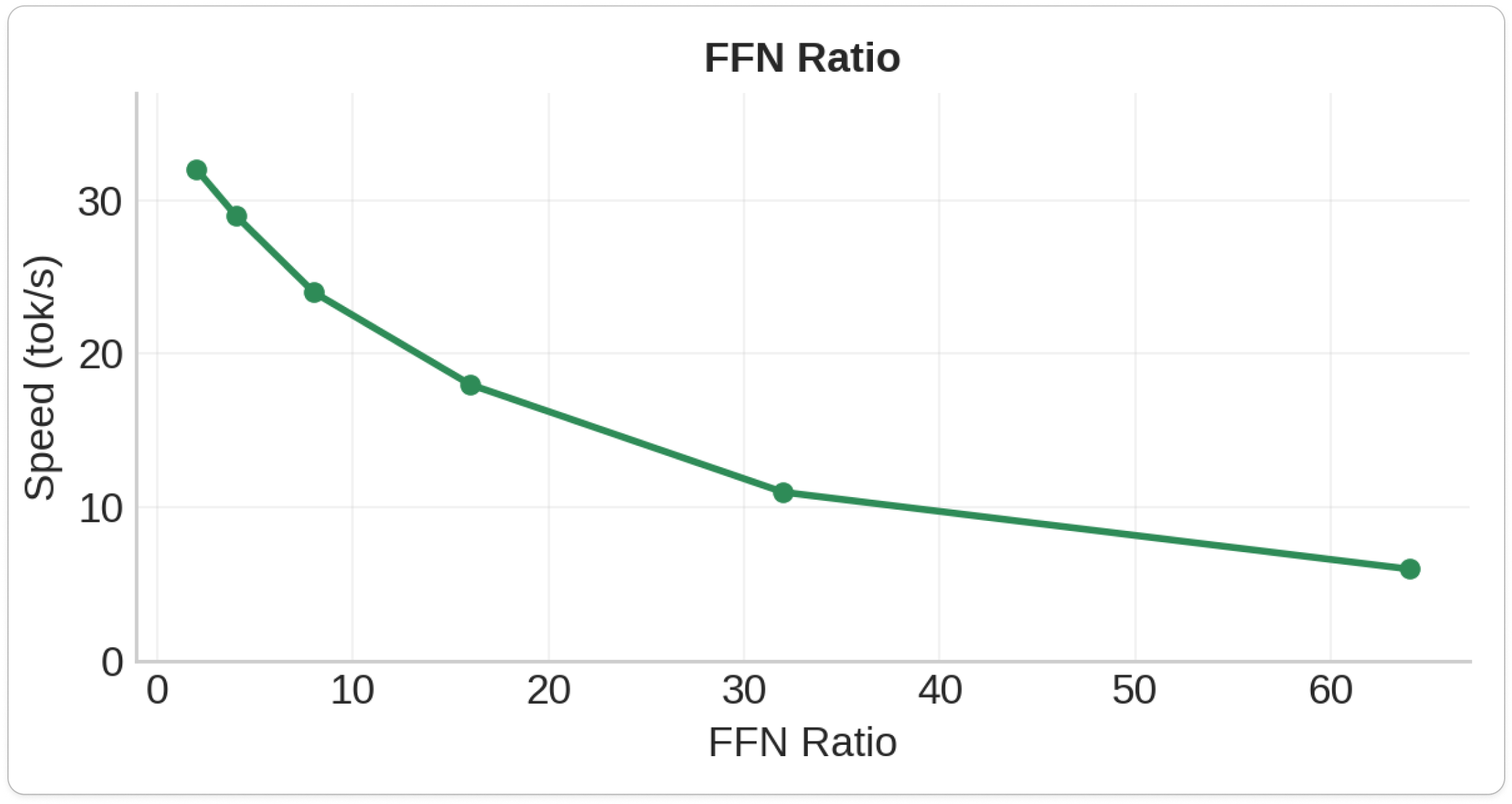
4.FFN Ratio
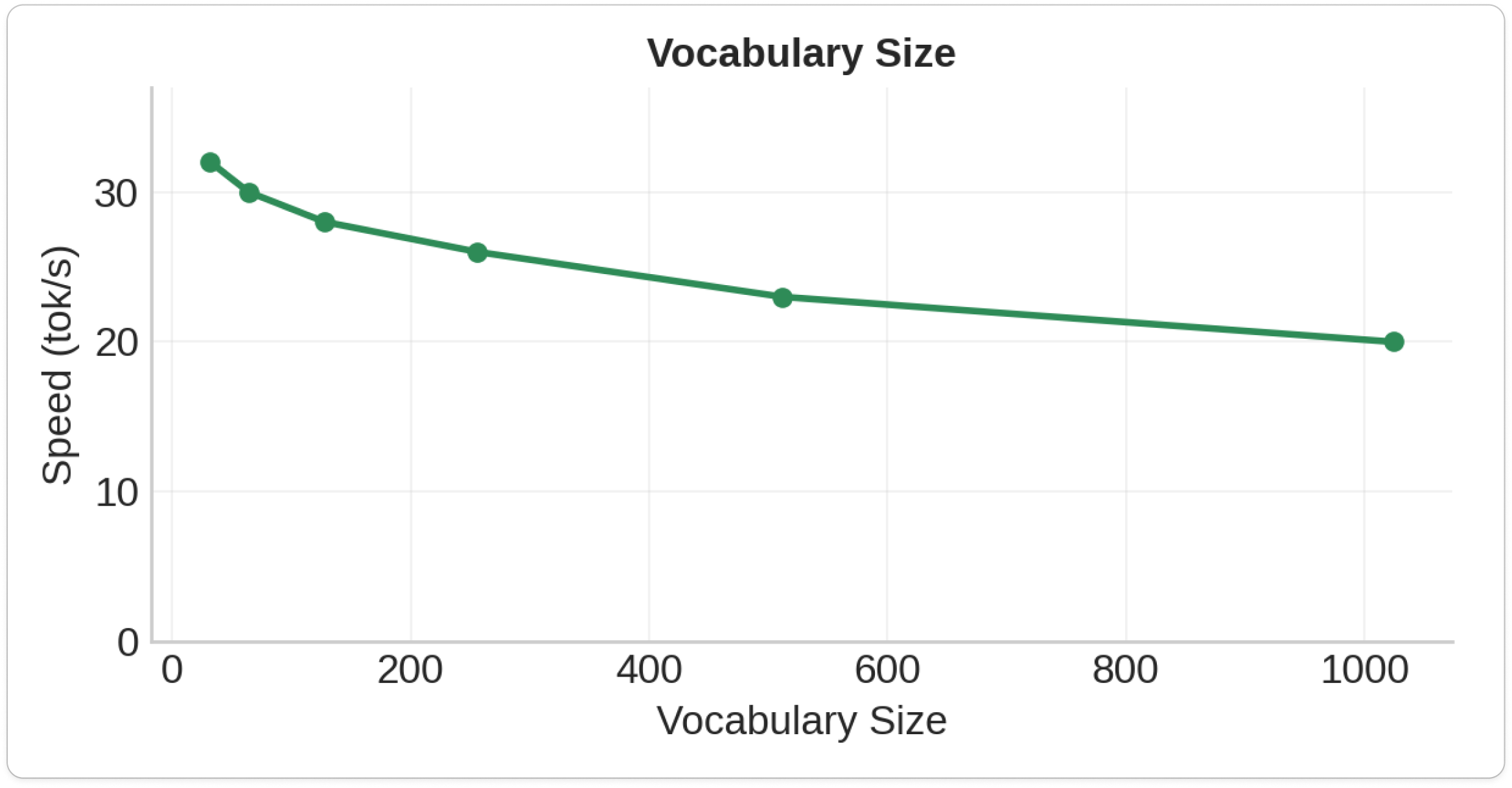
5.Vocab Size
Architecture Impact Hierarchy (Most to Least Critical)
- Dimension Size: 40-50% speed loss per doubling - the ultimate performance killer
- Layer Depth: 25-40% speed loss per additional layer
- Attention Heads: 20-25% speed loss per doubling (but surprisingly cheap at small scales)
- FFN Ratio: 15-20% speed loss per doubling
- Vocabulary Size: 8-12% speed loss per doubling (minimal impact)
Microcontroller-Specific Insights
Memory vs Speed Trade-offs
- Quantization paradox: Saves memory but slows down inference due to de-quantization overhead
- RP2040 bottleneck: Computation speed, not memory bandwidth
- KV caching: 3-7x speed improvement for multi-token generation
- Chunked loading: Eliminates large memory allocation failures
Production-Ready Findings
Practical Deployment Models
- 1K param models: 15-32 tok/s - real-time capable for interactive applications
- 8K param models: 2-3 tok/s - best balance of capability and reliability
- 10K param models: Near memory limits but can achieve 14.5 tok/s with optimal architecture
Architecture Templates for Production
# Maximum Speed (1K params)
optimal_speed = {
'vocab_size': 32-64,
'dim': 1-2, # Ultra-narrow
'hidden_dim': 64-128, # 64x-128x FFN ratio
'n_layers': 1,
'n_heads': 6-8,
'expected_speed': '20-32 tok/s'
}
# Balanced Production (8K params)
balanced_production = {
'vocab_size': 256-512,
'dim': 6-8,
'hidden_dim': 192-256, # 32x FFN ratio
'n_layers': 2-3,
'n_heads': 8,
'expected_speed': '2-5 tok/s'
}
Interesting things
- 176 architectural variants tested - most comprehensive microcontroller transformer study ever
- Ultra-narrow dimensions work at all scales (1K-10K parameters)
- Mathematical optimization provides elegant parameter allocation
- Speed scaling defies conventional wisdom - larger models can be faster with optimal architecture
Training Models
I trained the models on a H100 rented on Prime Intellect. Each model takes ~2 minutes to train.
All initial training took me 12 hours (about $20 total).
Results
- Fastest model: 32.0 tokens/second (1D architecture)
- Most balanced: 2-3 tokens/second (8K parameters)
- Memory limit: 256 vocabulary tokens maximum
- Architecture variants tested: 176 different configurations
Conclusion
Due to memory fragmentation on RP2040, the maximum vocabulary size we can use is 256, which is smaller than even the TinyStories models.
After spending $20+ in GPU for model pre-training, the models generate a few coherent words, which is promising. However, I decide to move on from this project.
People Seem to Love It on Reddit
https://www.reddit.com/r/LocalLLaMA/comments/1n1hro7/how_to_train_a_language_model_to_run_on_rp2040/