Train a tiny model to generate 3D files
 Training a Language Model to make 3D files
Training a Language Model to make 3D files
Background
Over my whole career, I have worked as a Mechanical Engineer, Robotics Engineer, Plumbing Engineer, Software & AI Engineer.

A consistent thread that shows is that: physical things take longer and more effort to create than software.
Armed with GPU credits from CloudRift & Prime Intellect + the generous free usage of Huggingface, I set out to build a language model to generate 3d files - CADMonkey.

1. Model architecture & 3d Programming Language
At Starmind, we need our models to be small enough to run on Raspberry Pi 4 & 5. Therefore, 1B is ideal, but the smaller the better. For this project, we picked Gemma3 due to its high intelligence and diversity of model sizes (270M, 1B, 4B, 12B).
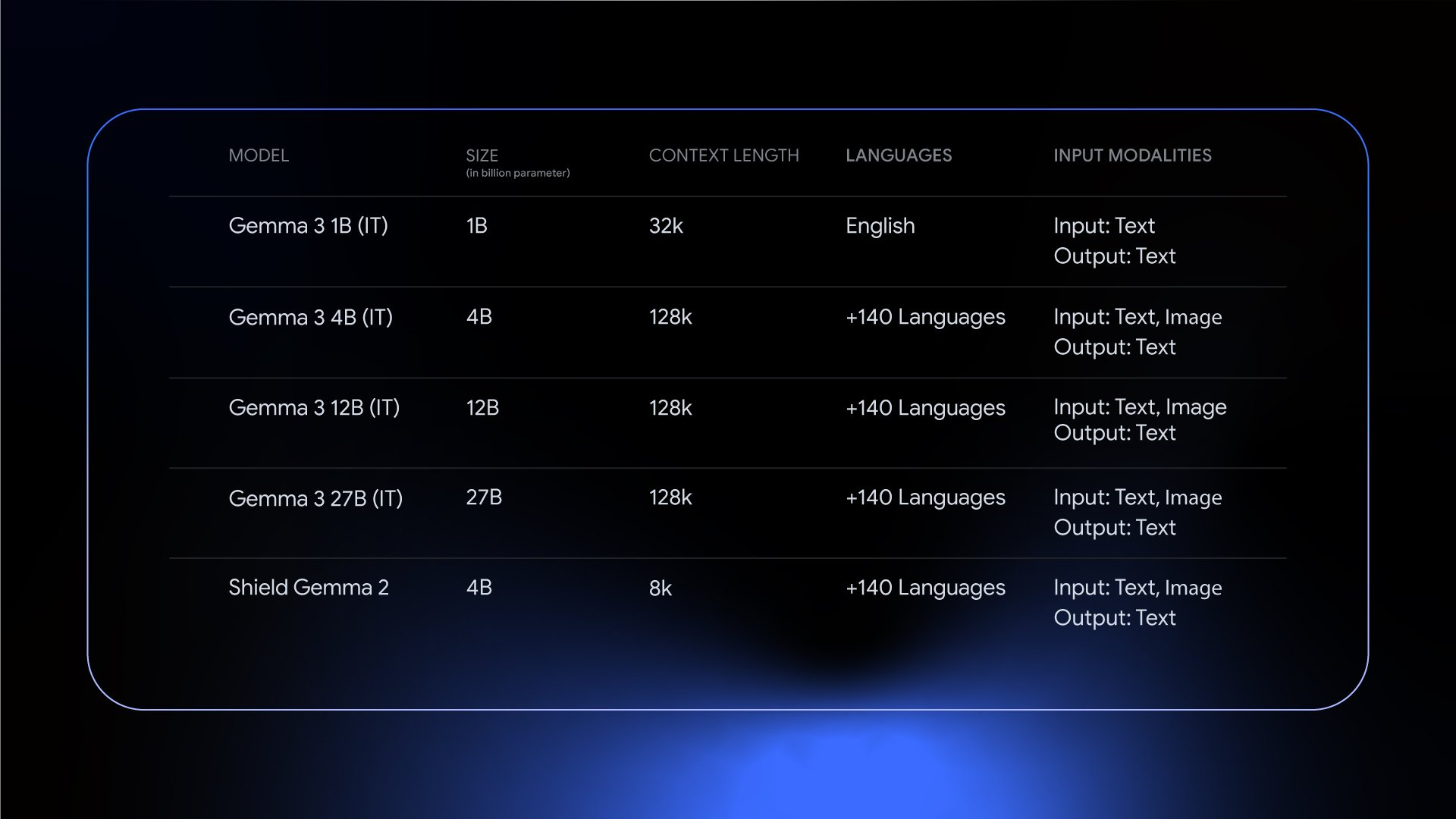
We also briefly considered a diffusion model, but the development complexity is too large. Perhaps we will revisit this idea another day.
The model we’re training will generate code that’s used to render 3D files. We chose OpenSCAD for its open-source nature, ability to be rendered on-device or on-browser, and its token efficiency (using less tokens to represent an object compared to other methods like Blender).
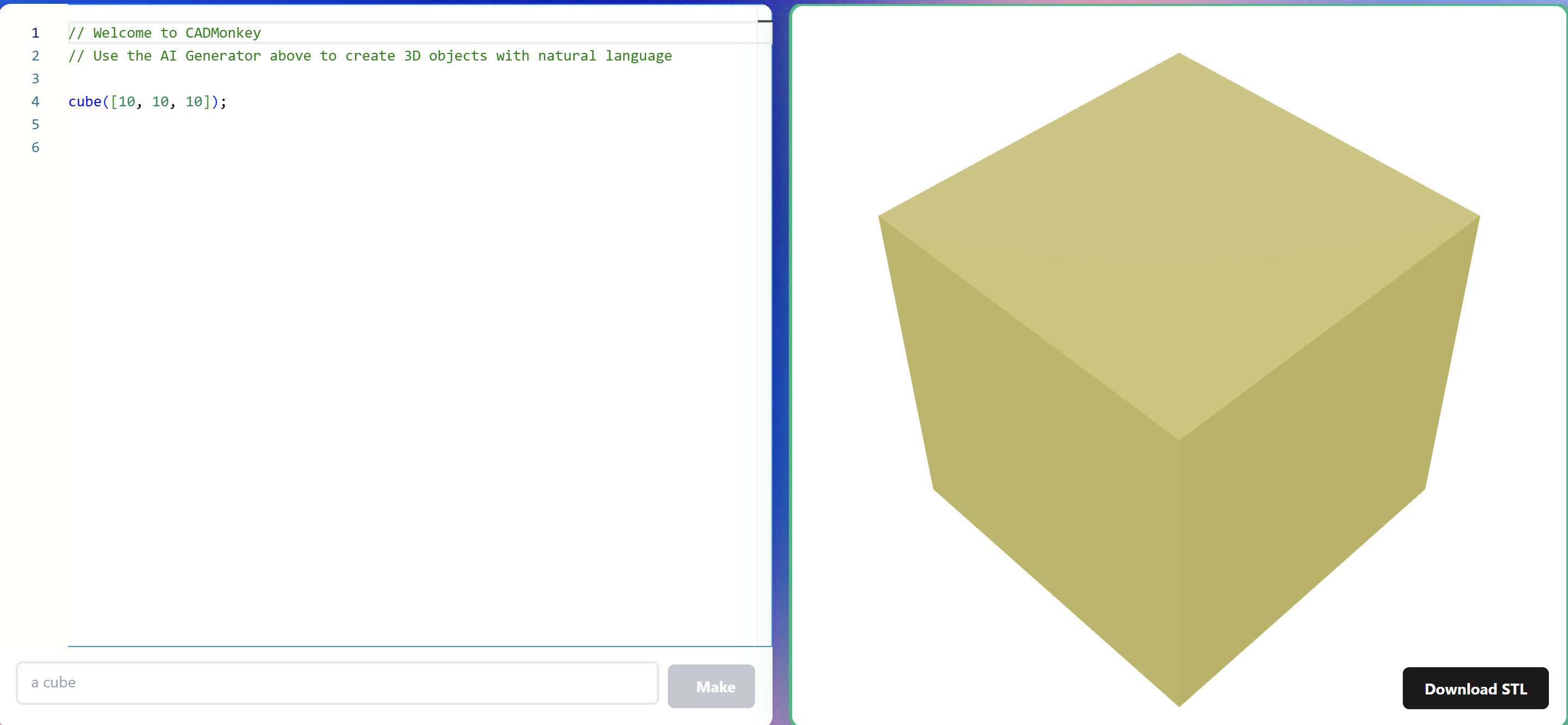
2. Dataset generation
If there is one thing you take away from reading this, it should be: a model is only as good as its dataset.
Here are the attempts we made at creating a dataset:
#1: There are 7,000 rows worth of open-source OpenSCAD dataset, scrapped from Thingiverse on Huggingface (redcathode/thingiverse-openscad). However, we have a few issues with this:
- The coding structure is overly diverse and the code is not well written. This caused the model after training to produce in-coherent code (a mix of Python & C).
- The objects present in the dataset are not common objects, instead they are “a specific gear for a specific thing” type. This fails to teach the model the semantic meaning of the code.

#2: Synthetic data generation is the method we chose to go with.
- First, we created a list of common object names by categories (animals, kitchen appliances, pokemon, etc). Then, ask a Large Language Model (Kimi) to generate the code, renders the code, and use a VLM (Qwen2.5-VL) to judge the output for ressemblance
The result is the following dataset: https://kdataset.web.app
This is the first synthetically generated & reviewed OpenSCAD dataset of large quantity on the internet: ThomasTheMaker/Synthetic-Object-v3 (35k rows of verified data).

This would not be possible without the grants provided by CloudRift. Thanks a bunch!
3. Mistakes we made along the way
There are many things we tried that did not work, and we hope it helps you avoid wasting time & efforts:
-
First, we tried generating data with Claude Sonnet & Haiku models on AWS Bedrock. The cost was estimated to be 40-60$ based on the token count. Due to reasoning tokens, this came out to $170 while the output barely surpasses open models like Kimi-K2 (non-thinking) and Deepseek-V2.
-
Second, we tried generating the list of object names through libraries and dictionaries. This was a bad idea as the list was quite random, containing objects that the base model did not even have any knowledge about.
4. Training
With the dataset ready, we fine-tuned Gemma3 270M, 1B & 4B models on the dataset with the following prompt:
‘hey cadmonkey, make me a {object name}’
This was done using Unsloth 4-bit finetuning.

The output model is converted into a GGUF model with q8 quantization.
Everything is available here: https://hf.co/collections/ThomasTheMaker/cadmonkey
5. Model evaluation
Evaluation is crucial yet tricky. We implemented a similar filtering pipeline to that of the dataset synthetic generation process
Prompt the model -> generate the code -> render the code -> ask Qwen2.5-VL to judge the render

The result is consistently around 75-80% rendering rate (aka does the code render?) & 20-30% VLM judge rate.
This remains quite consistent with all model sizes 270M -> 4B
Interesting findings:
- We also attempted fine-tuning on coding-specific models like CodeGemma & CodeLLama, but the model failed to generate coherent code. More work needs to be spent to learn why.
6. Make it available to the world!
First, I made a CLI application to run locally on Linux, MacOS & Raspberry Pi. It’s still available here: https://github.com/ThomasVuNguyen/MakeMe
Check out the full video here: https://www.reddit.com/r/LocalLLaMA/comments/1oavxt8/i_built_a_1b_cad_generator_model/
Second, I made it into a web application, cadmonkey: https://cadmonkey.web.app
In the first 12 hours of it launching on Reddit, 380+ models were created. I’m quite proud of that, since everything ran on the 30$ credits in Modal. 1-2 cents were spent every model.
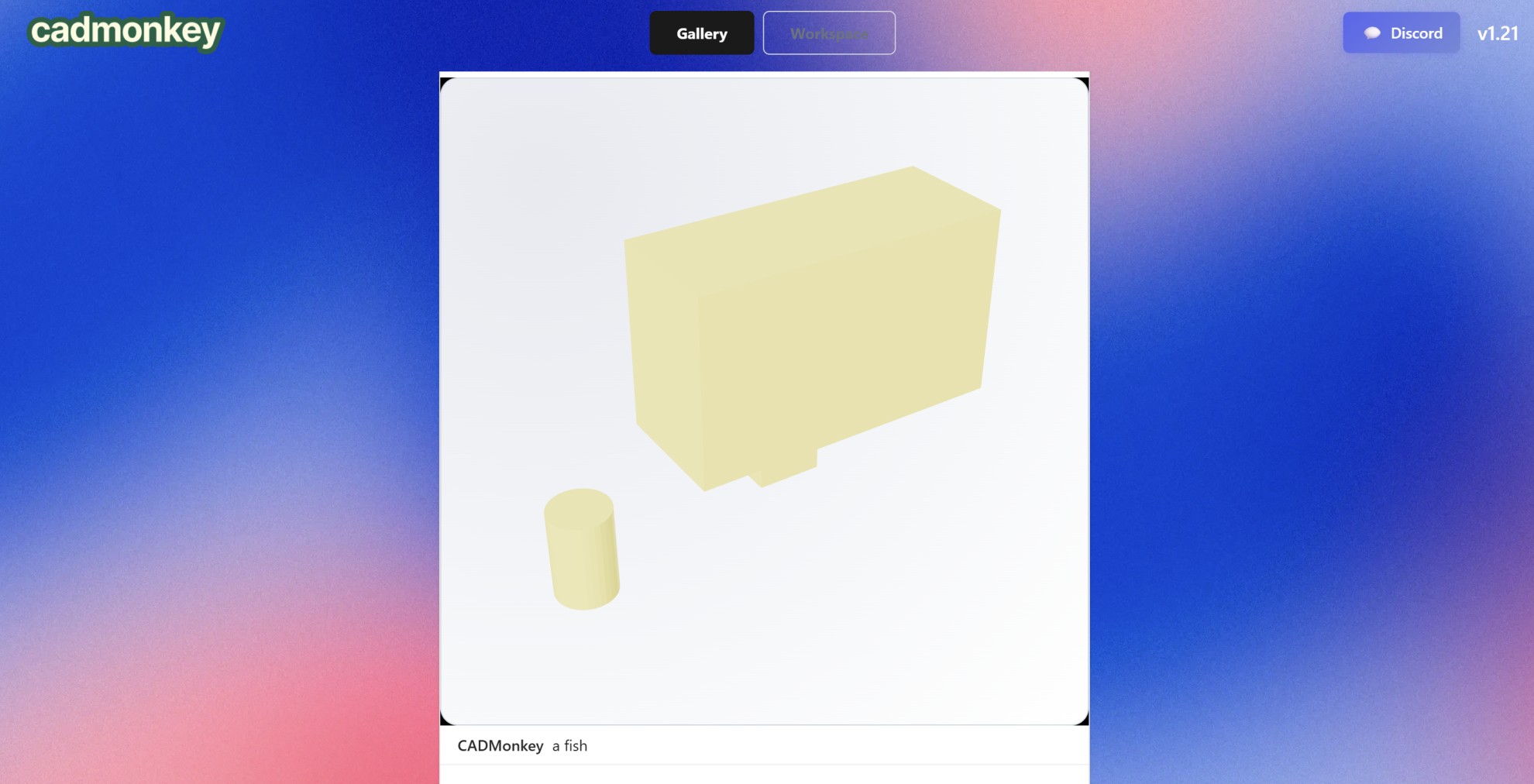
While most 3d models were combinations of random cubes and spheres, a user successfully made a duck (which I’m very proud of):
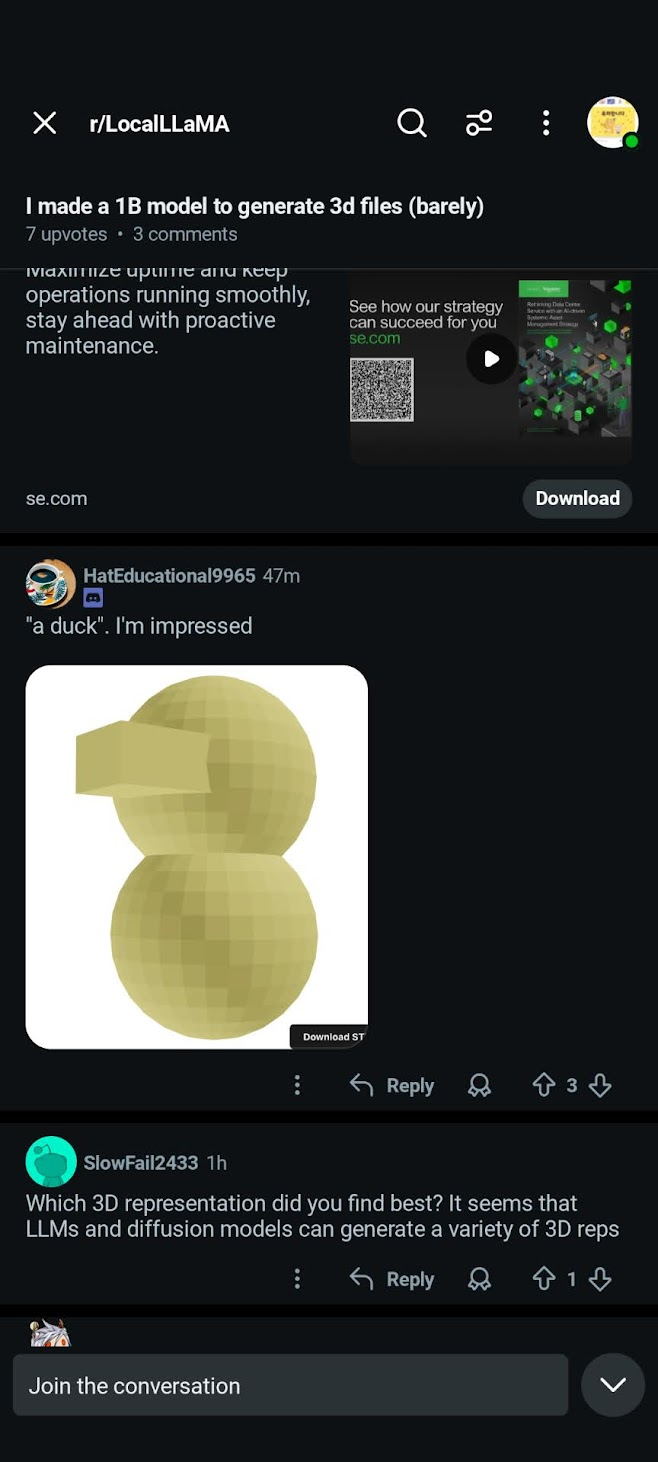
6. The takeaway
I know it’s cliche, but you can just make things!
5 years ago, it would cost me 5 figures and a team of 20 scientists to achieve this.
Now, I ran the whole experiments over 3 weekends, using 500$ in credits from various sources.
Up until now, my knowledge about Language Model was 1-year of obsessive self-taught.
You really can just do things. You just have to be crazy enough to start.
7. Some good news
We have onboarded a good friend, Rutvi onto Starmind as a volunteer/weekend contributor! She’s a ML intern of a company in the same startup incubator as my startup. She’s bright and eager to learn. I hope she stays that way.

I received the beta access & a grant from The Thinking Machine! It’s about to make my finetuning & evaluating workflow so much more efficient and affordable.

More good things will come if we work hard & do the right things consistently

Source code, useful links & sponsors
The dataset & model files:
Dataset generation & training code:
Awesome sponsors (: